Fast Typechecked Markdown Documentation with Clear Error Messages
Ólafur Páll Geirsson
8 Jan 2019
•
6 min read

This post introduces how mdoc evaluates Scala code examples with good performance while reporting clear error messages. mdoc is a markdown documentation tool inspired by tut.
Like tut, mdoc reads markdown files as input and produces markdown files as output with the Scala code examples evaluated. Unlike tut, mdoc does not use the Scala REPL to evaluate Scala code examples. Instead, mdoc translates each markdown file into a regular Scala program that evaluates in one run. In this post, we look into the implications of this change and how it can deliver up to 27x faster performance when processing invalid documents.
REPL semantics
A key feature of the REPL is that it shows you the value of an expression right after you type it. Although this feature is great for explorative programming, it can be limiting when writing larger programs.
For example, you get spurious warnings with -Ywarn-unused enabled.
$ scala -Ywarn-unused
> import scala.concurrent._
<console>:11: warning: Unused import
import scala.concurrent._
^
> Future.successful(1)
res0: scala.concurrent.Future[Int] = Future(Success(1))
Also, you get a warning when writing companion objects.
> case class User(name: String)
> object User
warning: previously defined class User is not a companion to object User.
Companions must be defined together; you may wish to use :paste mode for this.
Companion objects don't work out of the box because the REPL wraps each
statement in a synthetic object. We can look at the generated code by adding the
compiler option -Xprint:parser.
$ scala -Xprint:parser
> case class User(name: String)
package $line3 {
// ..
case class User(...)
}
> object User
package $line4 {
// ..
object User
}
It's not possible for object User to be a companion of class User because
they're defined in separate objects $line3 and $line4. This encoding is
required for the REPL because we need to eagerly evaluate each expression as its
typed. However, this limitation can be lifted if we know the entire program
ahead of time, which is the case when evaluating all Scala code examples in
markdown files.
Program semantics
Instead of using the REPL to eagerly evaluate individual expressions, mdoc builds a single Scala program from all code examples in the markdown file and evaluates them in one run. This approach is possible because we know which statements appear in the document. For example, consider the following markdown document.

This document gets translated by mdoc into roughly the following instrumented Scala program.
class Session extends mdoc.DocumentBuilder {
def app(): Unit = {
new App()
}
class App() {
super.$doc.startStatement()
val x = 1 ; super.$doc.binder(x)
super.$doc.endStatement()
super.$doc.startStatement()
val res0 = println(x) ; super.$doc.binder(res0)
super.$doc.endStatement()
}
}
The $doc.startStatement() and $doc.binder() instrumentation captures
variable types, runtime values and standard output from evaluating each
statement.
When Session.app() is evaluated, the mdoc instrumentation builds up a data
structure with enough information to render the document back into markdown.
There are many benefits to using this approach over the REPL:
- better performance, the document is compiled and classloaded once per-document instead of per-statement.
- language features like companion objects, overloaded methods and mutually recursive methods work as expected.
- compiler options like
-Ywarn-unused-importdon't report spurious warnings. - the mdoc instrumentation builds a data structure giving us control over pretty-printing of static types and runtime values.
However, one challenge with the approach is that compiler errors point to cryptic positions in the instrumented code instead of the original markdown source.
Clear error messages
It's annoying if compile errors show synthetic code that you didn't write yourself.
// error: generated/Session.scala:45:28 type mismatch;
// obtained: Int
// expected: String
val res0 = "hello".matches("h".length) ; super.$doc.binder(res0)
^^^^^^^^^^
Ideally, we want compile errors to point to the original markdown source instead.
// error: readme.md:10:17 type mismatch;
// obtained: Int
// expected: String
"hello".matches("h".length)
^^^^^^^^^^
To report readable error messages, mdoc translates positions in the synthetic program to positions in the markdown source. To translate positions, mdoc tokenizes both the original source code and the synthetic source code and aligns the tokens using edit distance.

Edit distance is used by tools like git and diff to show which lines have
changed between two source files. Instead of comparing textual lines, mdoc
compares tokens.
As long as instrumented sections like $doc.startStatement() don't contain type
errors, error messages reported by the compiler should translate to positions in
the original markdown source.
Evaluation
Let's test mdoc by running it on the http4s documentation. Http4s is a minimal, idiomatic Scala interface for HTTP.

We start by cloning the http4s repository and install the sbt-mdoc plugin.

Next, we run a migration script to convert tut code fences into mdoc code fences.
find . -name '*.md' -type f -exec perl -pi -e '
s/```tut:book/```scala mdoc/g;
s/```tut/```scala mdoc/g;
' {} +
Then we run sbt docs/mdoc and get a lot of compile errors.
> docs/mdoc
...
error: docs/src/main/tut/client.md:274:5: error: meteredClient is already defined as value meteredClient
val meteredClient = Metrics[IO](Prometheus(registry, "prefix"), requestMethodClassifier)(httpClient)
^^^^^^^^^^^^^
info: Compiled in 14.02s (46 errors, 36 warnings)
It's expected that there are compile errors because mdoc uses program semantics
instead of REPL semantics. For example, in this particular example
meteredClient was already defined in this document, which is not a problem for
the REPL but is invalid in normal programs.
We rename a few conflicting variables and comment out two ambiguous implicits.

We disable fatal warnings and run mdoc again but only for the modified document
dsl.md.
> set scalacOptions in docs -= "-Xfatal-warnings"
> docs/mdoc --include dsl.md --watch
info: Compiling 1 file to /Users/olafurpg/dev/http4s/docs/target/mdoc
I run when the future is constructed.
143303243 nanoseconds244212367 nanoseconds348637483 nanoseconds453423189 nanoseconds557908112 nanoseconds662361125 nanoseconds767036209 nanoseconds871488475 nanoseconds975876061 nanoseconds1081563422 nanoseconds
info: Compiled in 9.74s (0 errors)
Waiting for file changes (press enter to interrupt)
It took 10 seconds to evaluate the document for the first time. We insert a blank line and generate the document again and it only takes 3.5 seconds this time.

It's faster the second time because the JVM has warmed up. After 6 iterations of adding blank lines and recompiling it takes 2.4 seconds to generate the document.

We introduce an intentional compile error.

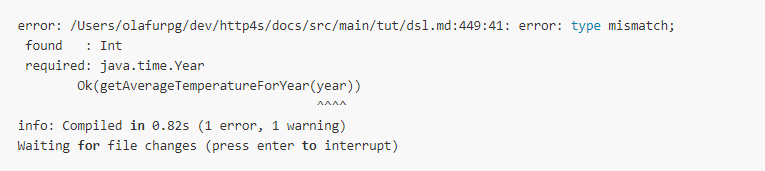
Observe that the error is reported within one second, faster than it takes to
process the document when it's valid. The position of the error message points
to line 449 and column 41 which is exactly where year identifier is
referenced. In some terminals, you can cmd+click on the error to open your
editor at that position.
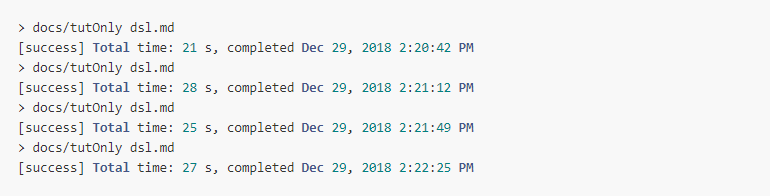
We compare the performance with tut by checking out the master branch and run
docs/tutOnly dsl.md four times.
We introduce the same compile error as before.

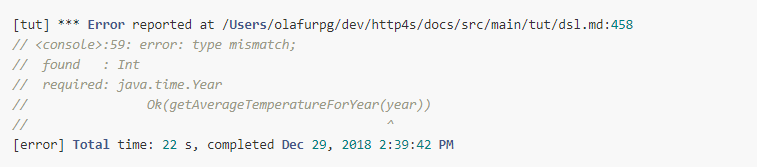
Observe that it took 22 seconds to report the compile error, about as long as it
takes to process the valid document. Also, the position points to line 458,
which is the last line of the code fence containing the closing }, but it's is
not the exact line where year is referenced.
Some observations:
- we had to make changes in the document to migrate from REPL semantics to program semantics. The migration can't be automated because it requires renaming variables and reorganizing the implicit scope.
- for cold performance, mdoc takes 10 seconds while tut takes 21 seconds to process a 500 line markdown document with 32 evaluated code fences. My theory is that the primary reason for this difference is REPL semantics vs. program semantics.
- for hot performance, mdoc processes the same document in 2.4 seconds while tut
takes between 21 and 28 seconds. Under
--watchmode, mdoc reuses the same compiler instance between runs allowing the JVM to warm up. I suspect tut can enjoy similar speedups by introducing a--watchmode. - mdoc reports compile errors for invalid documents in 0.8 seconds while it takes 22 seconds for tut. The reason for this difference is likely the fact that the REPL needs to compile and evaluate each leading statement in the document to reach the compile error (which appeared late in the document) while mdoc typechecks the entire document before evaluating the statements.
Conclusion
In this post, we looked into the difference between REPL semantics used by tut
and program semantics used by mdoc. Program semantics enable mdoc to process
valid markdown documents up to 2x faster under cold compilation, and report
compile errors for invalid documents up to 27x faster when combined with
--watch mode under hot compilation.
To report clear error messages, mdoc uses edit distance to align tokens in the original markdown source with tokens in the instrumented program. This technique enables mdoc to generate instrumented Scala source code while reporting positions in the original markdown source.
Migrating from REPL semantics to program semantics requires manual effort. If you write a lot of documentation and want a tight edit/preview feedback loop, the migration might be worth your effort.
Several projects already use mdoc: mdoc itself (this website), Scalafmt, Scalafix, Scalameta, Metals, Bloop, Coursier, Almond and fs2-kafka. Those projects may serve as inspiration for how to integrate mdoc with your project.
Ólafur Páll Geirsson
See other articles by Ólafur

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!