From $erverless to Elixir
coryodaniel
30 Aug 2018
•
9 min read

I recently rewrote a service that was on AWS API Gateway and Lambda in Elixir and apparently that intrigued some people, so I decided to do a small write up.
This post is going to be about our motivations for the move and what the replacement implementation looks like.
This post is not a critique of NodeJS, Lambda, or the Serverless movement, but a word of caution about how pricey it can become if your service ends up going webscale™.

What we started with
The original service was designed to collect an event stream from various web browsers collecting different client metrics and ingest them into a greater ETL (extract transform load) system. We had previously been using a 3rd party logging solution that was getting expensive and did not provide ways to extend or interact with the data we stored in the way we needed to.
Here is a very generalized diagram of the original system:
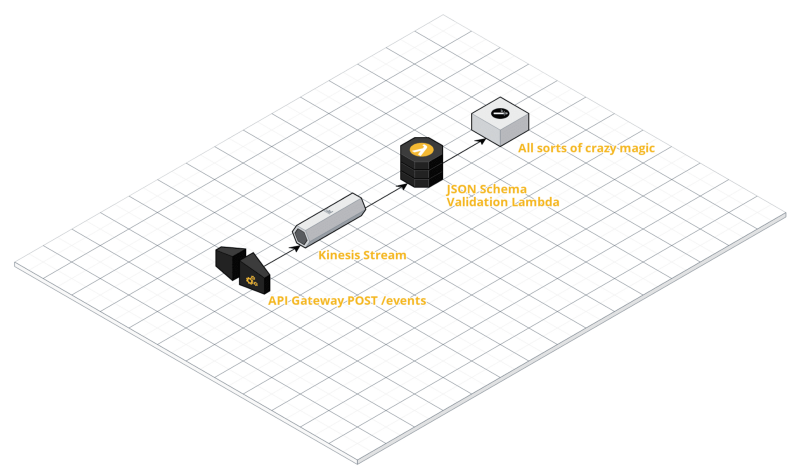
API Gateway
We bound our API Gateway endpoint directly to a Kinesis Stream using Velocity Templates so that the downstream Lambda function could take advantage of Lambda/Kinesis functionality and concurrently be invoked to process batches of HTTP POSTs. We knew that this service would be handling lots of HTTP requests at a time and did not want to run into throttling issues with Lambda, so processing off a queue in batches was a solid choice.¹
Kinesis
Our Kinesis Stream has varied in size a bit, but if I recall correctly at its highest throughput it took 60–80 shards to avoid getting WriteProvisionedThroughputExceeded.
Lambda
Our lambda was in charge of pulling batches off the queue, validating that the data made sense, collect metrics on our metrics², and ship off the results to a whole other land of magic to dispatch notifications, store replicas of data in S3 for posterity and compliance, manage log/event retention, and ingest events into a gigantic ElasticSearch cluster.³
So, to summarize:
- Each POST adds an event to a Kinesis stream
- A lambda pulls off about N-events⁴ at a time to process
- Everything is hunky dory (for now)
This system worked fantastically for well over a year. It scaled very easily. Required almost 0 attention. More teams and projects in the company began to interface with it. And then…

Then it got expensive.
Why we needed a change
API Gateway alone costs $3.50 per million HTTP requests. That’s awesome. I can run my side projects on it for free. I can build stuff in it rather quickly and get things done, but when it scales, so does the bill.
Our service didn’t quite grow exponentially in use, but it did hockey stick. It went from free, to a few hundred bucks, to around $12,000 just for API Gateway. No Kinesis. No Lambda. Just API Gateway.
We were doing about 5,000,000 requests per hour:
Rate / Million * Req / Hr * Hours in day * Days in month
$3.50 * 5 * 24 * 30 = $12,600.00
$12,600!!? Yeah, and again there are no lambdas even doing business logic yet, that’s just cash to get the events in. That spend is sustainable, but obviously a waste and we knew that we were going to be adding additional load to the system in the near future.
Currently we are processing up to 12,000,000 events per hour. Let’s do the math on if we had stayed on API Gateway and Lambda:
Rate / Million * Req / Hr * Hours in day * Days in month
$3.50 * 12 * 24 * 30 = $30240.00
$30,240 Oof, glad we dodged that one.
From bleeding cash to “let it crash”
^ That’s an erlang joke.
So a lot of people asked me:
Why not Go?
I’ve only written a few CLIs/TUIs and created a few PRs in Go. I am not, nor do I pretend to be a Go guru. We had a system running at a high scale and I couldn’t risk building it in something that I did not know how to write efficiently and operate.
Aside: I did build the prototype in Rust for fun one weekend, but it felt irresponsible to deploy with it given I have absolutely 0 Rust experience.
Why not Node? It was already written in Node.
Actually, most of the cost consuming parts were written in Terraform (to deploy it all) and Velocity Templates (to do some inflight request manipulation to ingest into Kinesis). The node lambda was rather simple. It pulled off batches, validated them, and sent them on their way down a second kinesis stream.⁵
If I was going to set up my own Express server (or whatever) then it would just be replacing the API Gateway portion and my goal was to replace the Gateway and Lambda in one operation. Get the preliminary Kinesis stream out of there. This lambda was originally processing batches and shipping off batches, now the function handling individual requests would also need to handle the batching. We did not want to hit Kinesis with a single record at a time.
So, if I built it in Node, I would either have to hack up some global variable to save my state in or depend on some external data store like Redis or Memcached.
Why not Cobol?
No one asked me that.
But why Elixir?
- This system has to be up when the rest of our world falls apart. This tool is used for debugging issues in client software that runs on a lot of high traffic websites.
- It also has to be absolutely fast. The client library is sending lots of information per page load in a lot of our customers’ apps. We can’t go slowing down our customers’ users’ experience. At the same time we decided, since we are running our own HTTP interface, that now we should give feedback (400 BadRequest) if the data is invalid to the developer per request instead of making them look at a reporting tool down the line. Keep the user’s experience good, make the developer’s experience better.
- It’s cool and I enjoy writing and reading it 😎.
- I can take advantage of language features to reduce the need for external dependencies like Redis or Memcached.
Actually letting it crash
Like all software projects, I shipped this to production and I got everything right the first time and it worked fantastically. Everyone patted me on the back and said “good job.” We shared egregious high fives and people actually carried me around the office on a chair over their heads.
JK, I screwed this bad boy up a few times and I’m pretty sure I set a server on fire somewhere in an AWS region.
My first attempt
Handling the HTTP request is the easy part, but I had to batch up data to ship off to Kinesis. One way is to use the AWS Kinesis HTTP API, but they also have a Kinesis agent that I’ve run on plenty of servers. So I figured I would just use Elixir’s built in Logger module and run a sidecar container with the Kinesis Agent configured to ship my logs. Dead simple.
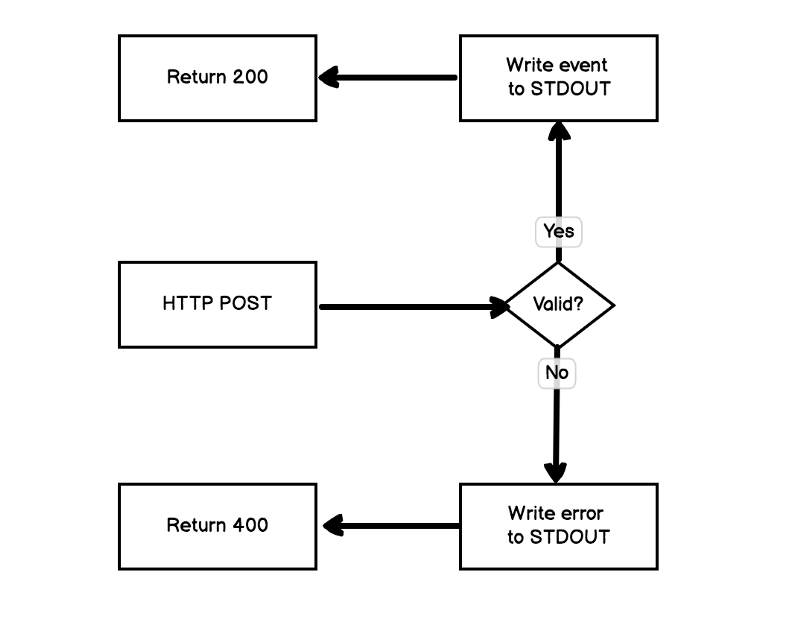
Well, that blew to bits quickly. The Elixir standard Logger mentions:
Alternates between sync and async modes to remain performant when required but also apply backpressure when under stress.
Pfft. There is no way I’m going to trigger the back-pressure mechanism…
I don’t recall the exceptions off hand because this was the quickest I’ve ever shut down a multi-variate test or rolled back code, but I drove the Logger straight into the ground. Request times sky rocketed, memory went off the rails, and I started seeing all sorts of crashes in the Logger process. Steam started coming out of everything and I swear I saw a sprocket fly off.
I just kinda backed away slowly from that approach.
My second attempt
I wanted to make sure I circumvented any back pressure, I needed to keep the requests super fast. So I replaced the Logger module with a simple write to a file that the kinesis agent could read from. Writing files in Elixir also happens through a process, but you can open up raw access to a file.
defmodule EventStream.Storage.File do
@behaviour EventStream.Storage
@newline "\n"
@log_file Application.get_env(:event_stream, :log_file)
def write(msg) do
File.write(@log_file, msg <> @newline, [:raw, :append])
end
end
I am using a behaviour (an interface in other languages) for storing data. This allows me to have a nice easily inspectable implementation of the store in my test suite.
This actually worked amazing. Request times dropped so low I thought it wasn’t working, but then…
RAM went crazy.

Things are obviously askew when a web server is using 10GB of RAM. This wasn’t Elixir’s fault. It wasn’t Kinesis’s fault either.
Anyone know what it was?
I mentioned “sidecar container” above. This is running in Kubernetes and the three containers (Elixir, Kinesis, Logrotate) are sharing a volume. That volume behind the scenes is running with tmpfs which is an in-memory filesystem. I could change it to disk based, but then I realized my goal was to lower dependencies and now I was sitting in a container full of them. Was Logrotate deleting files before the kinesis agent parsed them? ¯_(ツ)_/¯ I hope not!
My third attempt
All those dollar sucking besos from Mr. Bezos made me forget that time honored software principle: KISS.⁶
Keep it simple, me.
The solution was a few GenServers.
For people not from the Erlang or Elixir world, GenServers are a tool for implementing the client-server relationship and allows for storing state and processing work asynchronously with a simple API. It’s built into the language and a fair amount of language features are built on top of it.
Here is an over-simplified diagram of my supervision tree.
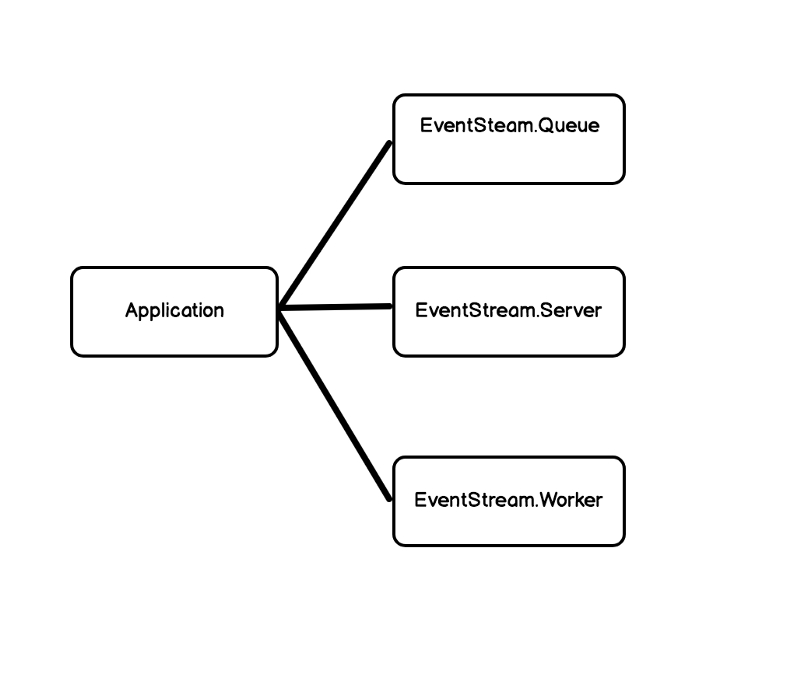
-
Server: supports async or sync calls from HTTP requests to place an event. Async responds fast with a 201, sync responds with any validation errors. This allows developers working on an integration to ask for errors when they are debugging, but run efficiently when releasing code to clients.
-
Queue: holds batches of work. Kinesis supports up to 500 items at a time up to 5MB in size. This queue gets pummeled by requests and internally it stores sets of batches. When the count or size is exceeded, it asynchronously sends a batch to the Worker.
-
Worker: makes calls to Kinesis PutRecords via a library called ex_aws. If any events fail to write, they are placed back into the Queue to be reprocessed.
The Queue GenServer is configured to trap exits and also dispatches events to the worker when it receives an exit.
This has been working fantastic. Response times are sub-second and resource utilization is almost constant.
Here is a graph of CPU vs RAM during our high traffic time.

And the numbers:
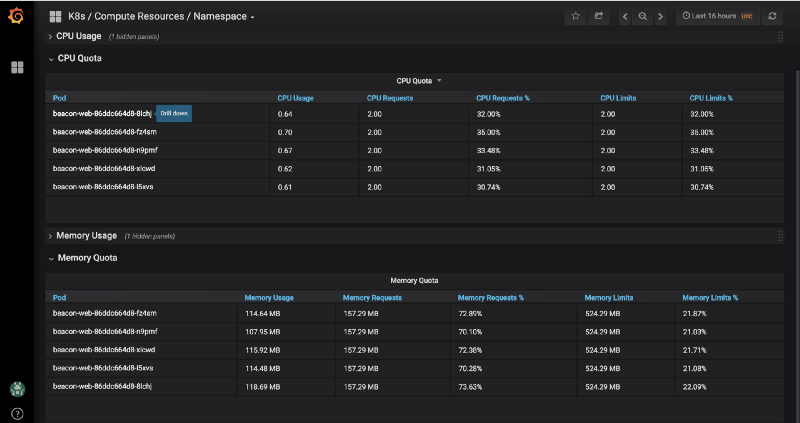
The CPU usage per Elixir node ranges between 0.6 to 1.8 under very heavy load. RAM stays pretty consistent in the 100 to 150MB range, although I currently over provision just in case :D
How does this compare cost-wise?
It’s a lot cheaper for us. Mind that we already have an ops team and we already have a Kubernetes cluster running. Our additional costs are the fractions of EC2 instances that the Elixir nodes are consuming. I could argue that it’s free since they are running on leftover compute, but for comparison with the numbers above I’ll calculate the cost. I’ll use CPU since that is what this service is mostly constrained by.
Our general kubenetes instance group is running on t2.2xl’s that cost $0.4416 per hour and have 8 vCPUs each, so that makes $0.0552 / vCPU / hour.
We are currently running 3 to 5 elixir nodes using between 0.5 to 2 CPUs each.
On the lower end:
$0.0552 * 0.5 (lower cpu) * 3 (nodes) * 24 (hours) * 30 (days) = $59
On the high end:
$0.0552 * 2 (upper cpu) * 5 (nodes) * 24 (hours) * 30 (days) = $397
We haven’t had an Elixir node using above 1.8 CPUs and on average we are running 4 nodes at 1.1 CPU:
$0.0552 * 1.1 (cpu) * 4 (nodes) * 24 (hours) * 30 (days) = $174
So, should everyone go and rewrite there Serverless services in Elixir? Roll out Kubernetes? Get a nose piercing? Absolutely not.
A good part of this entire system still runs in Lambda, although it will be moving into Elixir over time to make it easier to reason about and develop on locally.
What everyone should do is think about where your service is going, and can you afford those costs when you get there. If you don’t have a team of ops people and you aren’t familiar with serverful stuff, spending $30k/mo on HTTP requests might be cheaper than an ops team.
But, if you do have the team, the know how, or will, once you hit scale there is a lot of room for savings by running your own infrastructure.
Footnotes
- A downside of this approach was to developers using this (async) service we returned 201s and were unable to tell them at the time if the data they sent was valid and ingestible. They would have to use some additional tooling to see if their events made it to where they were supposed to go.
- This system uses itself to monitor different aspects of itself like ratios of malformed events, throughput, and workflow step counters.
- The back half of the system is still in Lambda and NodeJS, but the invocations are tiny in comparison to what was being invoked by lambdas exposed to user interaction.
- 2000 events was our sweet spot for real-time rendering of graphs.
- You may be thinking, that sounds like that can be replaced with a Kinesis Firehose Transform function. It could be. I wasn’t aware of (or it didn’t exist) at the time the system was originally designed and now that we need to get off of API Gateway, it doesn’t matter. It is a rad feature though.
- My word play is out of this world.
coryodaniel
See other articles by coryodaniel

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!