How to build a SOLID Distributed Systems
Carlos Hernandez Navarro
24 Jun 2020
•
4 min read

Today I will be sharing my knowledge about distributed systems with you and what I’ve learnt from the last few years working on it. As we can see in the header picture I would like to define the distributed systems as a [clockwork](https://www.merriam-webster.com/dictionary/clockwork#:~:text=Definition%20of%20clockwork,device%20(such%20as%20a%20toy), where there are several individual pieces that have to work together in harmony and precision.
The two keys in a distributed system are the services and the connections between them.
In this first article, I’m going to start by talking about how to extrapolate the SOLID principles to the infrastructure and how it helps us to improve our architecture.
SOLID in distributed systems
As programmers we are familiar with this concept, we bear it in mind every time we create a new piece of code. So why do we not use these principles in our distributed systems? To clarify this concept I would like to show you an example where I will be transforming a monolithic application into distributed systems.
Imagine that we are working at VideoTube’s company, and they have a monolithic application where users can register and upload videos.
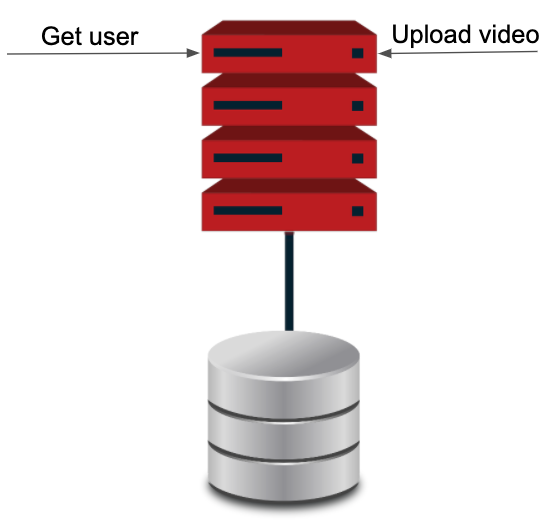
As we see in the previous image the system consists of a single service (monolithic application). This application is online and VideoTube currently has 200 users operating in a small country every hour. The users and bosses are really happy with the new app, for this reason they decided to expand the app to other countries. But as we start opening the service to new countries problems start to arise. Every hour more and more users are uploading videos into our system and at the same time everything inside our system slows down, even the user information which has a low load average. Here we can see the current situation:
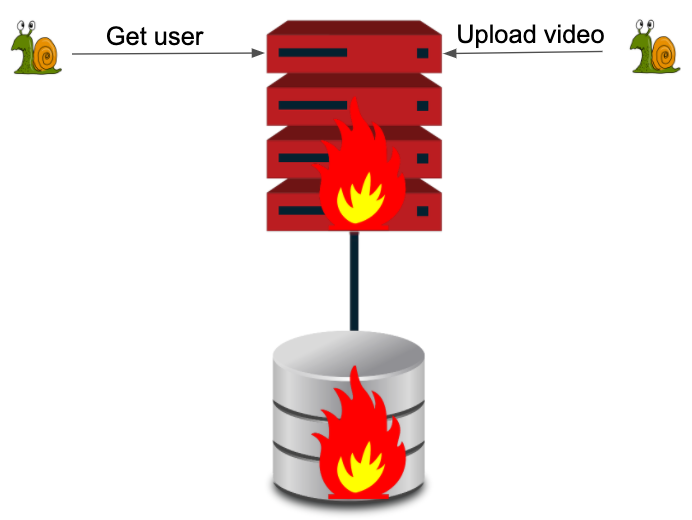
We can see that the whole system is overloaded because we have a lot of workload on the video side. Here we have several alternatives to solve this problem:
-
Scale our infrastructure (vertical scaling) more CPU, RAM…
-
Scale the service (horizontal scaling) and balance the traffic between both applications.
-
Split our application by boundaries using the Single Responsibility from SOLID
Perhaps we think that horizontal scaling could solve this problem, but it is not easy to scale this application. What do we do with the database? Do we have to duplicate the database as well? Is it a good idea to duplicate the user information in the database when the problem is on the video side?…
In this case the best solution is to split the service by boundaries applying the Single Responsibility principle.
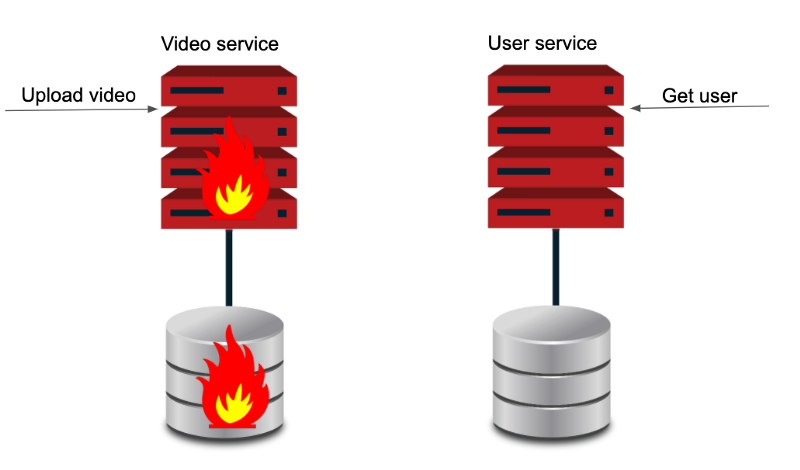
Now we have two independent services with two different databases, at this point we could decide to use different types of storage for our data. In our case it makes sense to have a relational database to save the user information on and a file system combined with a non-relational database for the videos.
Now the services are working in isolation. Any future problems that occur in one of our services will not affect the rest of the system.
This system has a few more benefits, for example, we can just scale the video service, fix a bug in our user service and deploy it in isolation at the same time users are uploading videos.
Wow! We have the perfect system and everyone is happy at the company. But happiness does not last forever- a new feature is coming from the marketing department. They want to show how many upload videos they have in the user’s profile. Ok, so the first implementation that comes to mind is the idea of implementing an endpoint in the video service to get the number of videos per user:
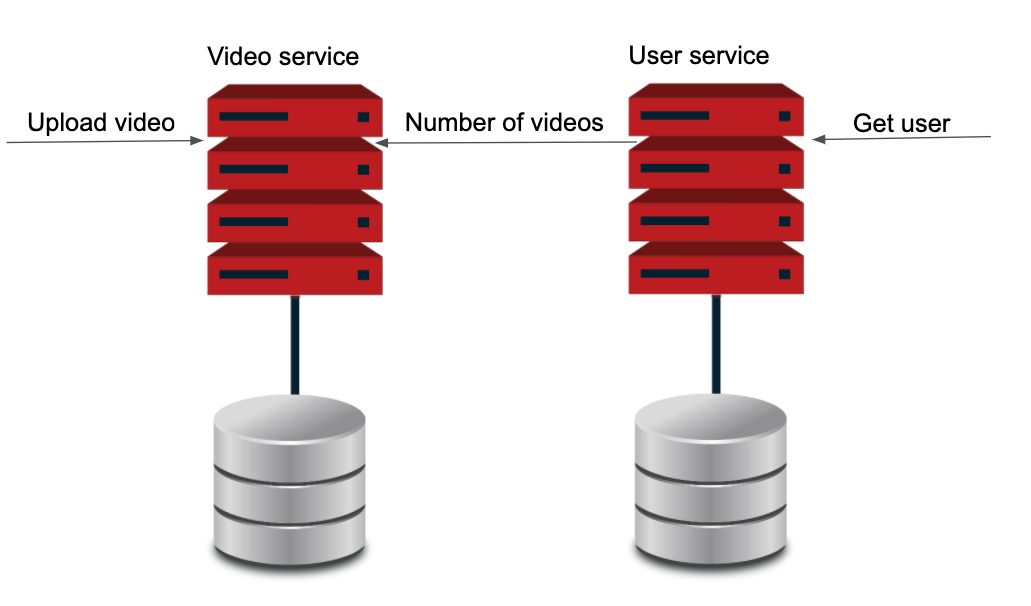
As we are going to see this implementation is not a viable option because each time we need to show the user’s profile we need to call the end point in the video service and now both services are coupled again. For this reason, we go back to the start box:
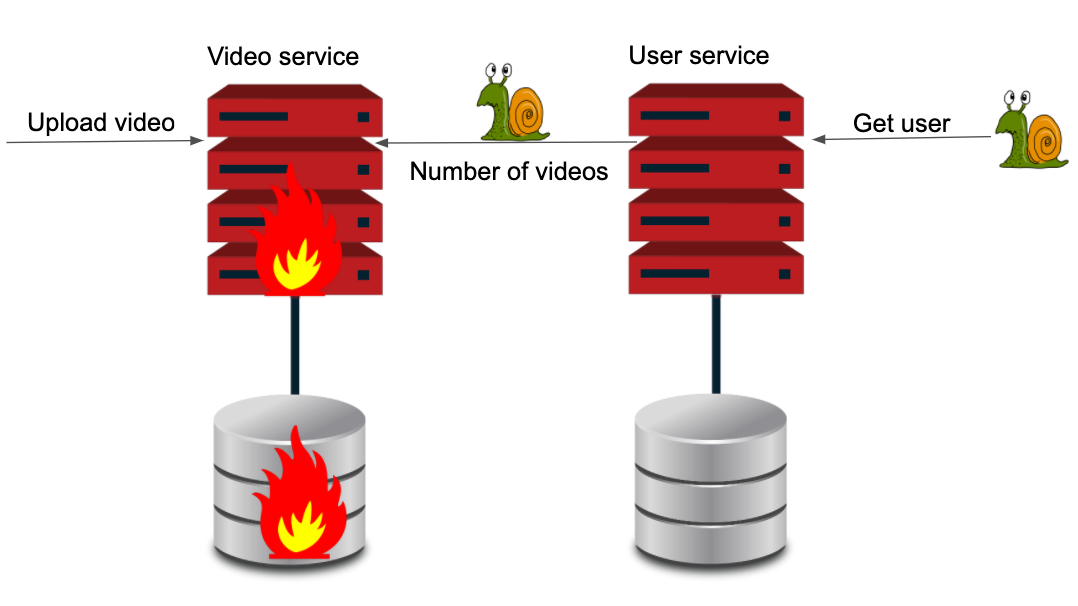
Again, we have a performance problem in our user services because of the video service. Can we improve this? The answer is yes, in this situation we can apply the dependency inversion principle from SOLID to our system (see below).
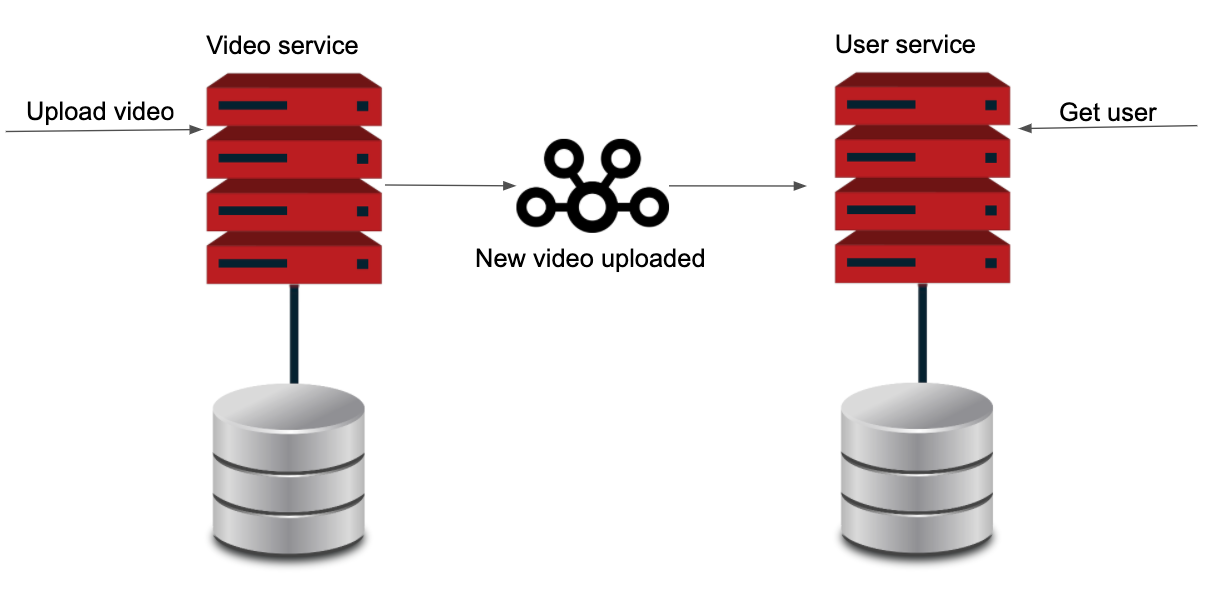
In the final stage we apply dependency inversion principle through event-driven. Every time that a video is uploaded to the system, the video service is going to create an event and publish it in our queue system. On the other side, the user service will be subscribed to the queue system to receive these events. Each time that an event is available it will be read by the user service and the user’s information will begin updating. Now both systems are decoupled again.
Now our infrastructure is SOLID. In addition to what was discussed previously, we have implemented the Interface Segregation principle where each service has its own API, and the Open-closed principle where we can extend the functionality of our system by adding new services instead of modifying the current services.
References
Carlos Hernandez Navarro
Programmer analyst with 3 years of work experience. For the last year, I have been designing a high performance analyst application for an aeronautical company. The main technologies used on this project are: Java Spring boot, kubernete (Openshift), Kafka, Jenkins and Oracle.
See other articles by Carlos

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!